Integrate with Third-party Systems Seamlessly
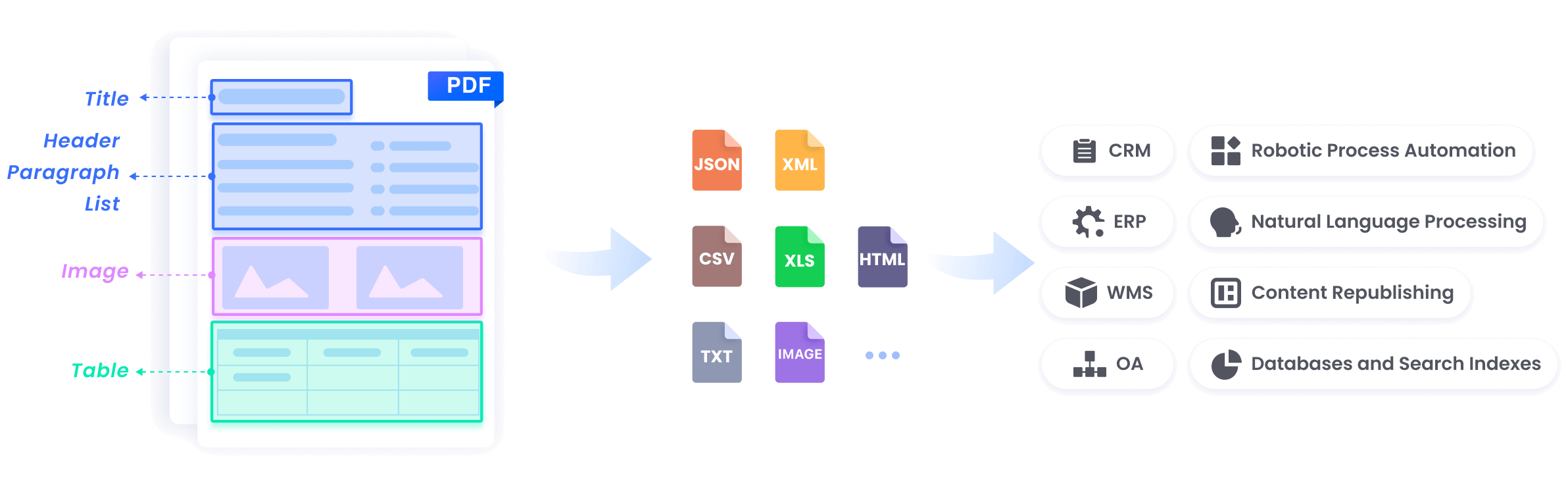
Offer High-quality Data for LLM Training

Multiple Deployment Options
Self-hosted Deployment
Securely batch delete, watermark and extract data from documents within local environments with libraries for Java and .NET on Linux, Windows, and macOS, ensuring enhanced control and privacy.
Offline SDK
Seamlessly integrate local SDKs into your apps or systems with rich functions including viewing, markup, editing, signing, conversion, and data extraction, satisfying the needs of processing documents in different scenarios.
Open API/ Low-Code
Explore faster and more flexible APIs and low-code solutions to smartly process documents from any platform, liberating developers from platform and server restrictions.
Flexible Licensing Models: Subscription, OEM, and More
Why Choose ComPDF AI
98%
Customer Satisfaction
95%+
Renewal Rate
15 Years
15 Years in PDF Solutions
15+ Years
Senior Engineering Support
Apply Now for a Customized ComPDF AI Solution for Your Project!
I have read and agreed to the Service Terms and Privacy Policy . (The data you submit is treated confidentially and will never be disclosed to third parties.)
Customers Brand Wall, ComPDF Worth to Trust














