
In today’s data-driven world, extracting tabular data from PDFs is essential for businesses, but the PDF format’s structure often makes data extraction challenging. JSON, a lightweight and flexible format, is ideal for storing and analyzing this data. This article will show you how to use ComPDF to efficiently extract tables from PDFs into JSON format, enabling easy access and editing of table information.

Method 1: Convert PDF to JSON Using Python
ComPDF provides secure and reliable PDF APIs to help developers integrate powerful PDF features into their applications, enhancing the user experience. What's more, Open API offers a 30-day free trial, allowing you to process over 200+ documents without limits to test your project needs. With its comprehensive API documentation, you can easily find tutorials on extracting PDF tables to JSON in various languages such as Java, PHP, and Python.
This article will show you how to use Python to extract tables from PDFs to JSON.
Step 1: Register and authenticate
You can sign up for a free Open API account online and get unlimited free processing of over 200+ documents for 30 days to test your project.
Open API uses JSON Web Tokens method for secure authentication. Get your Public Key and Secret Key from the control panel and authenticate it as follows.
# Create a client
client = CPDFClient(public_key, secret_key)
Step 2: Create a PDF to JSON task
Choose the PDF to JSON tool and substitute it with the accessToken you obtained earlier. Change the error message's display language to your preferred language type. Afterward, the taskId will be included in the response data.
# Create a task
# Create an example of a Image to Json task
create_task_result = client.create_task(CPDFConversionEnum.PDF_TO_JSON)
# Get a task id
task_id = create_task_result.task_id
Step 3: Upload files
Upload the PDF file from which you need to extract the table as JSON, and bind it to the task ID.
# Upload files
client.upload_file('test.pdf', task_id, file_parameter)
Note: You need to set the option parameter of extracting content to "1"
Step 4: Convert PDF table to JSON
After the file is uploaded, call this interface through the task ID to convert the PDF document to JSON.
# Execute task
client.execute_task(task_id)
Step 5: Get task information
Request task status and file-related metadata based on the task ID.
# Query TaskInfo
task_info = client.get_task_info(task_id)
Now, your code should be like the following sample:
# Create a client
client = CPDFClient(public_key, secret_key)
# Create a task
# Create an example of a Image to Json task
create_task_result = client.create_task(CPDFConversionEnum.PDF_TO_JSON)
# Get a task id
task_id = create_task_result.task_id
# File handling parameter settings
file_parameter = PDFToJSONParameter()
file_parameter.is_allow_ocr = file_parameter.ALLOW_OCR
file_parameter.type = file_parameter.TYPE_TEXT
# Upload files
client.upload_file('test.pdf', task_id, file_parameter)
# Execute task
client.execute_task(task_id)
# Query TaskInfo
task_info = client.get_task_info(task_id)
If you want to use other development languages for converting PDF to JSON, you can visit Open API libraries. It also offers comprehensive guides for more PDF features, including document editor, annotations, and more.
Method 2: Extract PDF Tables to JSON With ComPDF
ComPDF's data extraction feature uses advanced table algorithms to accurately identify and extract both standard and non-standard tables from PDFs, with support for outputting data in formats such as JSON, XML, and CSV. Today, we will demonstrate how to extract tables from a PDF to JSON on the Windows platform.
1. Set the input file, and output file path and create a class to extract PDF tables as JSON.
string inputFilePath = "***";
string outputFolderPath = "***";
string outputFileName = "***";
CPDFConverterJsonTable converter = CPDFConvertFactroy.CreateConverter(CPDFConvertType.CPDFConvertTypeJsonTable, inputFilePath) as CPDFConverterJsonTable;
2. Set extraction options, including whether to enable OCR and AI layout recognition.
CPDFConvertJsonOptions jsonOptions = new CPDFConvertJsonOptions();
jsonOptions.IsAllowOCR = false;
jsonOptions.IsAILayoutAnalysis = false;
3. Call the Convert interface to start extracting PDF
ConvertError error = ConvertError.ERR_UNKNOWN;
converter.Convert(outputFolderPath, ref outputFileName, jsonOptions, ref error);
When you are finished, your complete code should look like the following example:
string inputFilePath = "***";
string outputFolderPath = "***";
string outputFileName = "***";
CPDFConverterJsonTable converter = CPDFConvertFactroy.CreateConverter(CPDFConvertType.CPDFConvertTypeJsonTable, inputFilePath) as CPDFConverterJsonTable;
CPDFConvertJsonOptions jsonOptions = new CPDFConvertJsonOptions();
jsonOptions.IsAllowOCR = false;
jsonOptions.IsAILayoutAnalysis = false;
ConvertError error = ConvertError.ERR_UNKNOWN;
converter.Convert(outputFolderPath, ref outputFileName, jsonOptions, ref error);
Here are 2 samples of the affection of recognizing a table with the help of ComPDF:
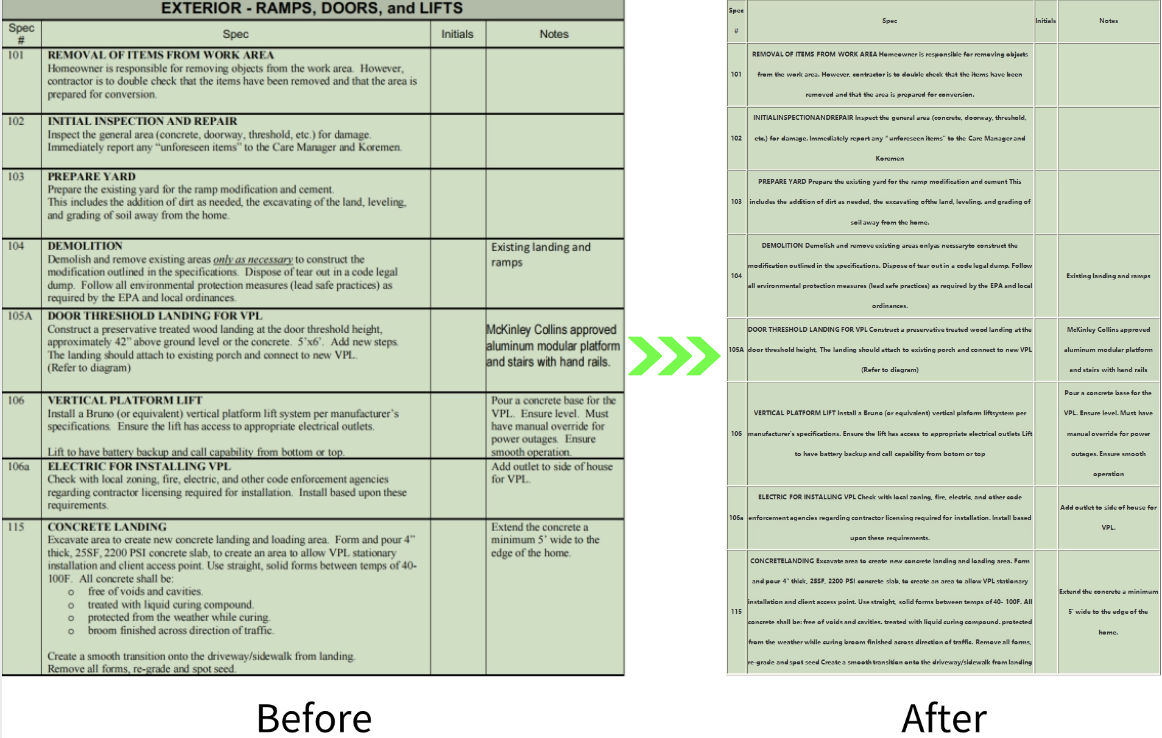
1. Standard Table
Recognition effect for standard tables with complete and clear table borders and inner lines:
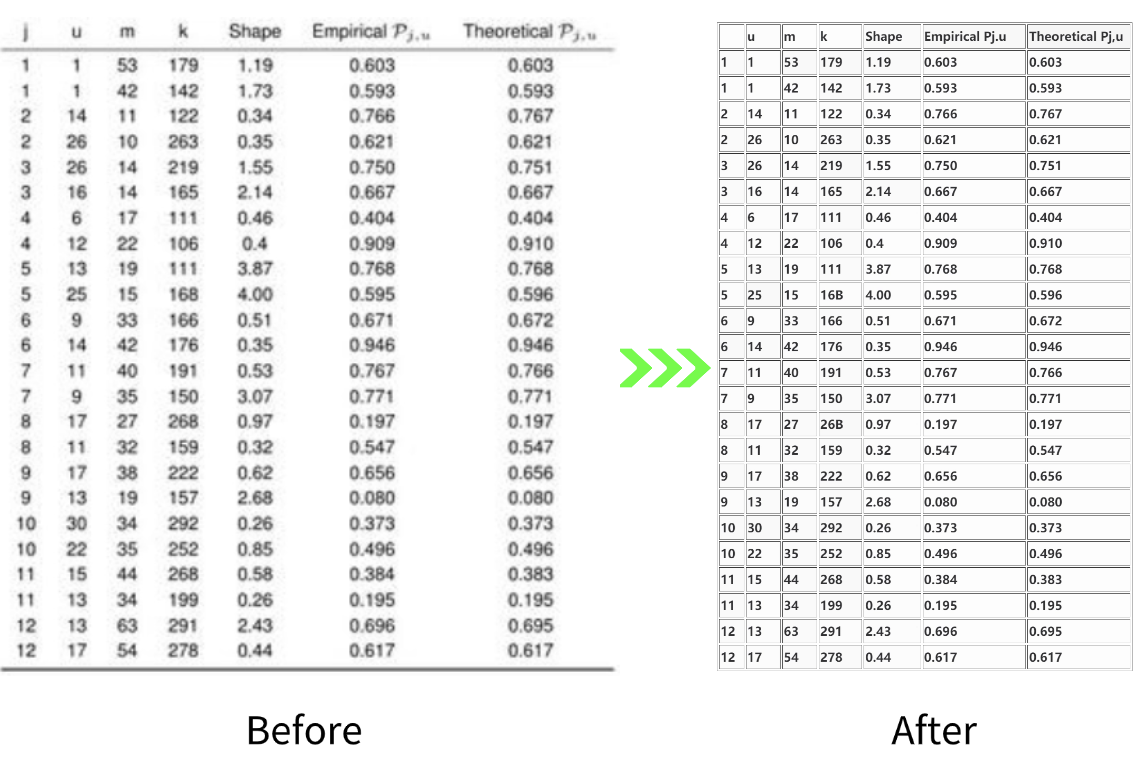
2. Non-standard Table
Recognition effect for non-standard tables with missing table borders or inner lines and unclear table lines:
In addition, you can get a complete tutorial and code examples on extracting PDF tables to JSON on more platforms by visiting the ComPDF Data Extraction guide document. ComPDF supports users to test the project by getting a 30-day free trial online!
Final Words
This guide shows you how easy it is to use ComPDF to extract PDF tables as JSON for storing and editing table data.
ComPDF offers responsive services to users, including 24/5 online technical support, unlimited error requests, and remote assistance to address any technical issues and ensure smooth project progress.
Additionally, you can instantly try out the ComPDF online tools to extract PDF documents into JSON format for free or convert PDF tables into other editable text formats, such as Excel spreadsheets!