Extract PDF To JSON
Overview
Extract text, tables and images from PDF documents to Json file.
Standard table and non-standard table
Commonly, tables can be divided into two categories: standard tables and non-standard tables. The specific definitions are as follows:
- Standard table: The table border and the inner lines of the table are complete and clear. There is no need to manually add table lines to divide the table content.
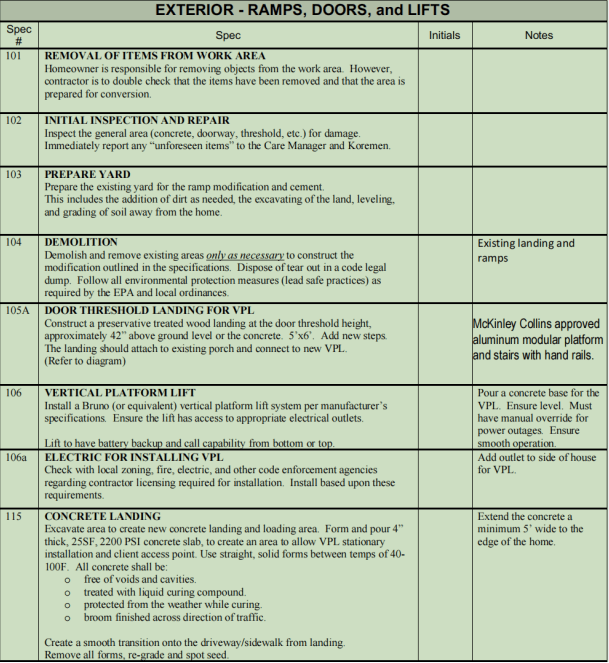
- Non-Standard Tables: Tables lacking borders or clear inner lines, requiring manual additions of table lines to separate contents.
Table Extraction Option
ComPDF Conversion SDK supports the option json_contain_table, when enabled, will extract table content from PDFs and output the table structure; otherwise, table content will be treated as regular text.
Notice
- Without enabling AI layout analysis or OCR options, tables in the original PDF cannot be extracted. It is recommended to enable AI layout analysis or OCR for high-precision table recognition.
Sample
Full sample code which illustrates the text extraction capabilities.
c++
ConvertOptions opt;
// Extract PDF to JSON.
CPDFConversion::StartPDFToJson("json.pdf", "password", "path/output.json", opt);